Name des Teilnehmers: Christopher Krauß
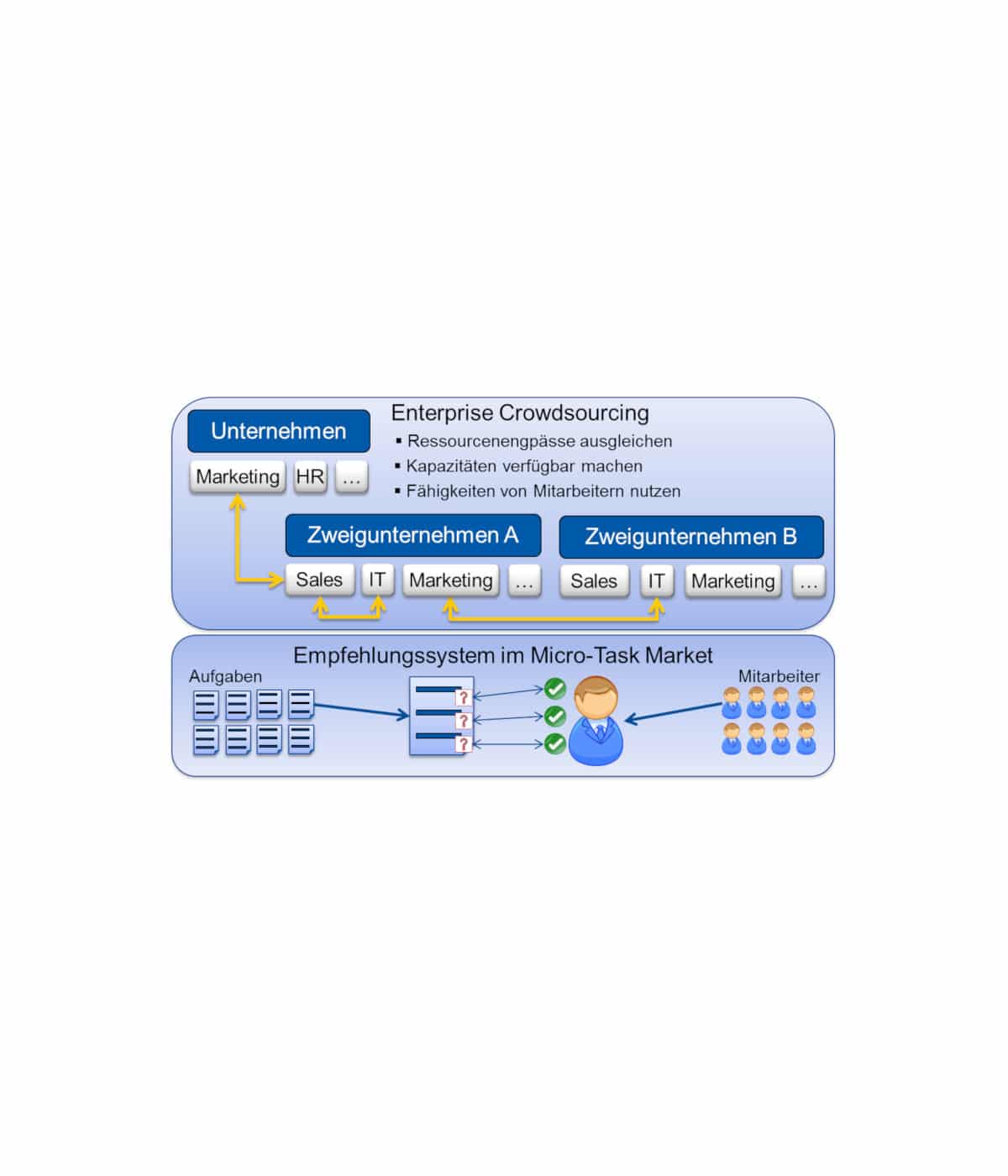
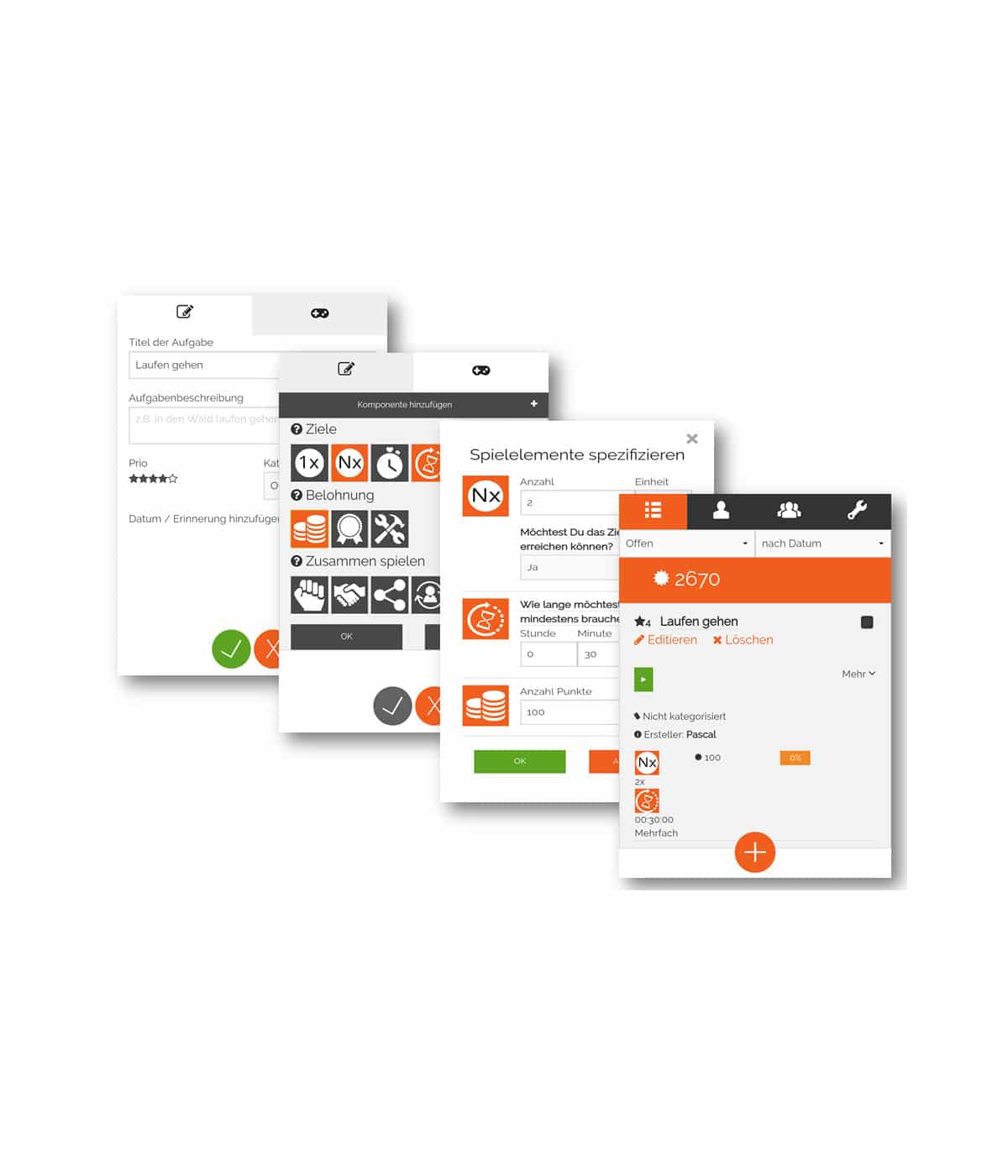
Beschreibung des IT-Forschungsprojekts: Bei der Verarbeitung von Big Data in modernen Internetdiensten fehlen oft wichtige beschreibende Informationen über die Benutzer sowie die angebotenen Dienstleistungen und Produkte. Diese sind für die Vorhersage zukünftiger Nutzungsverhalten durch gängige Data-Mining-Algorithmen unerlässlich. Die fehlenden Daten sollen über Kontext-sensitive Analysen zusätzlicher Quellen erfasst, als wiederverwendbare zeitbasierte Ontologien abstrahiert und für die Verwendung durch Empfehlungsalgorithmen optimiert werden.
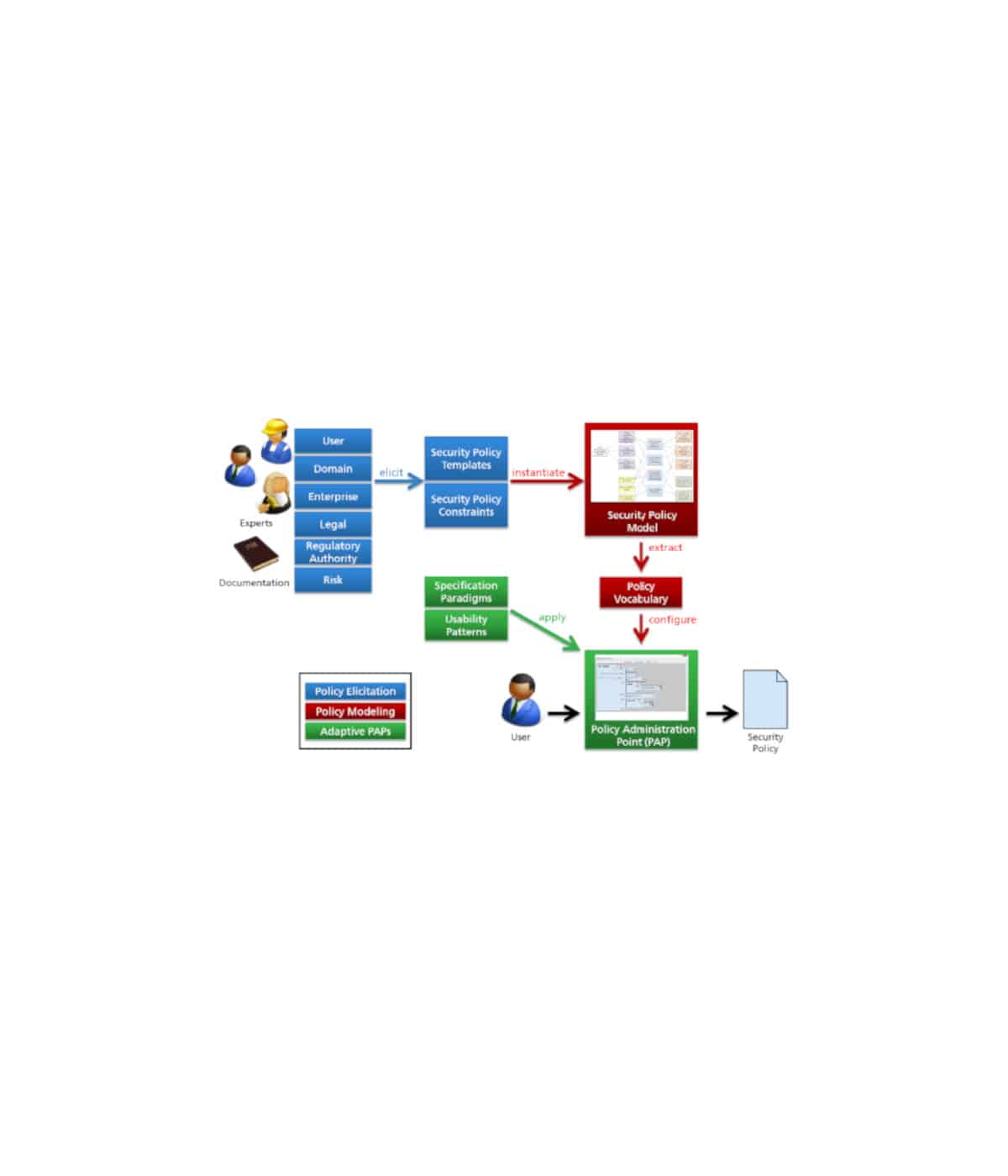
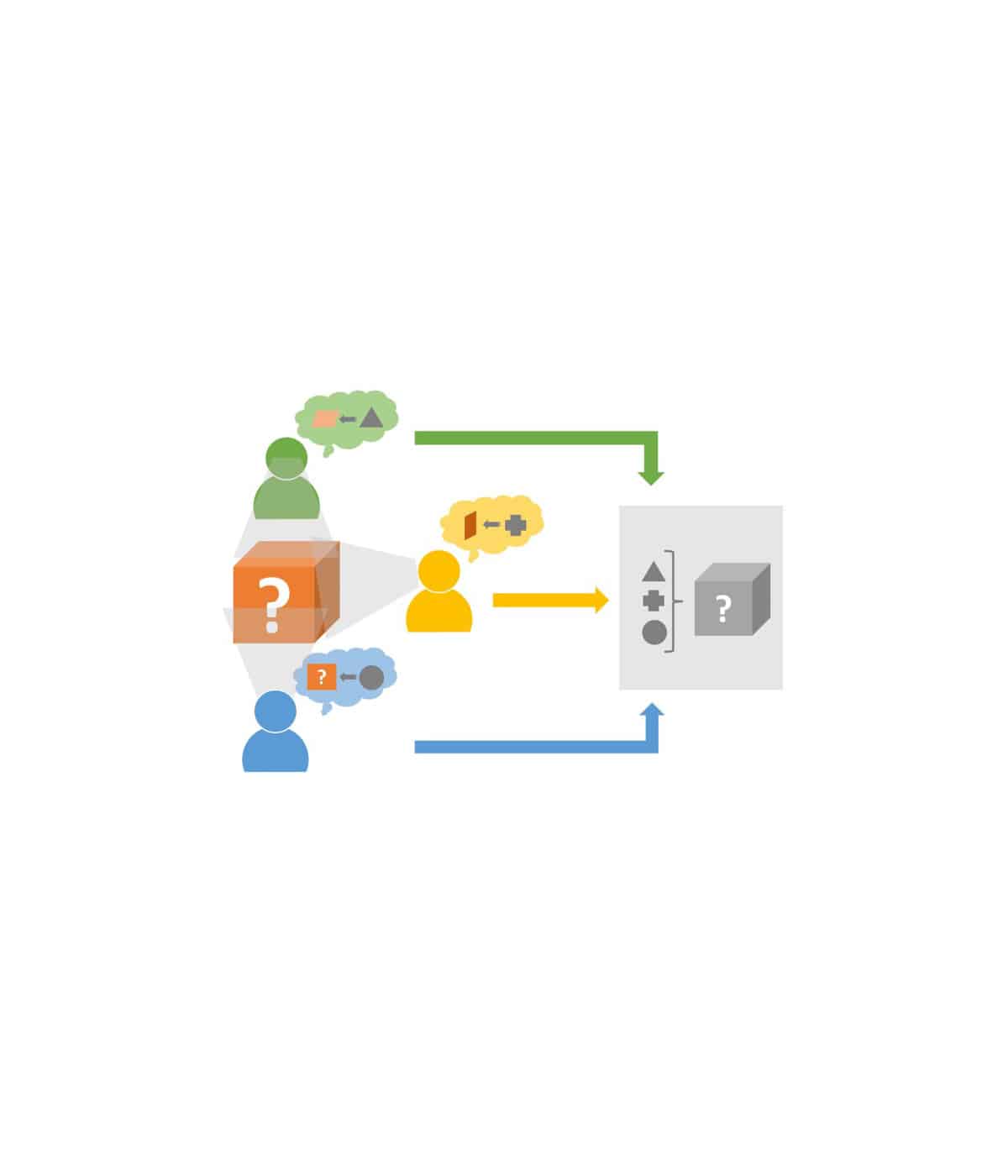
Bekannte Probleme von Empfehlungsalgorithmen, ergeben sich durch den sogenannten Kaltstart (Cold Start Problem). Dieser tritt immer dann auf, wenn keine oder nicht ausreichend Daten über den User, die Items oder den Kontext, der für die Berechnung kontext-sensitiver Einflüsse wichtig ist, existieren. Verwandt dazu ist das Sparsity Problem, welches die viel zu geringe Anzahl an Benutzerfeedback – beispielsweise in Form von Bewertungen, Likes, Views etc. – vieler Empfehlungssysteme beschreibt. In der Folge können viele Collaborative und Knowledge-based Filtering Algorithmen nur sehr ungenaue Vorhersagen errechnen und die Akzeptanz der Konsumenten sinkt. Wenn darüber hinaus auch beschreibende Meta-Daten nicht vorhanden sind, schlagen meist auch Content-based Filtering Algorithmen zur Errechnung von Ähnlichkeiten fehl.
Viele der notwendigen Daten existieren zwar im World Wide Web, liegen aber meist in unstrukturierter Form bei fremden Service Providern vor und haben meist keinen Zeit- oder Kontext-Bezug. Ziel ist eine signifikante Verbesserung der Empfehlungsalgorithmen vom Neustart bis zum langanhaltenden, dauerhaften Betrieb des Systems mit Hilfe von Zeit- und Kontext-sensitiven User-Item-Daten. Dazu müssen sowohl beschreibende Daten, die eine bessere Vergleichbarkeit von User oder Items im Verlauf der Zeit ermöglichen sollen, als auch Kontext-abhängige Interessensdaten eines Benutzers gewonnen und trainiert werden.
Weitere Informationen zum Projekt finden Sie hier.
Software Campus-Partner: Fraunhofer Verbund IuK-Technologie, Holtzbrinck Publishing Group
Umsetzungszeitraum: 01.03.2015 – 31.08.2017