Name des Teilnehmers: Maximilian Scherer
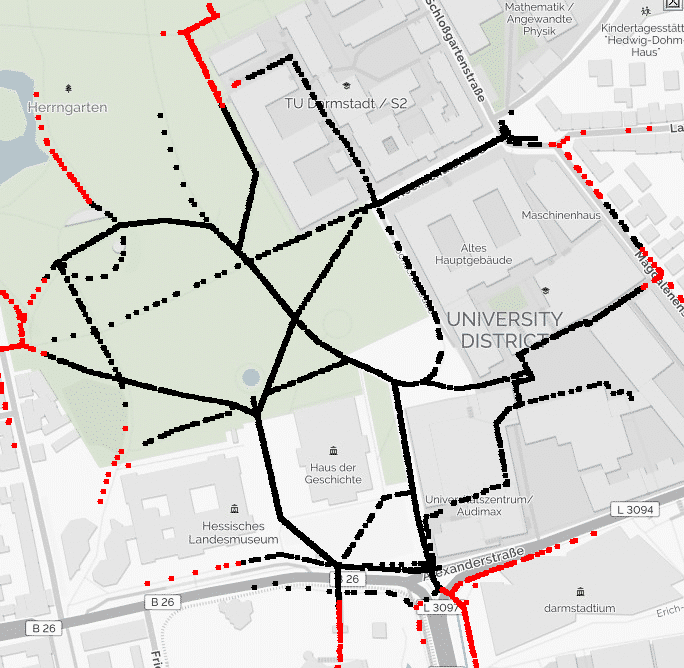
Beschreibung des IT-Forschungsprojekts: Sowohl in der Forschung, als auch in Anwendungsfällen von Industrie und Handel werden immer größere Mengen an Daten erhoben. Dies umfasst den Bereich der Forschung, zum Beispiel in der Physik, Chemie und der Klima-Forschung, aber auch diverse industrielle Anwendungen, z.B. zur Qualitätssicherung, zur Maschinenüberwachung oder im Controlling. Die Auswertung dieser enormen Datenmengen hat zum Ziel, Abhängigkeiten zwischen einzelnen oder mehreren Variablen zu erkennen, die auf funktionale und kausale Zusammenhänge hindeuten und zur Optimierung von forschungs- oder geschäftsrelevanter Prozesse herangezogen werden können. Aufgrund der Datenmenge und der zum Teil mathematisch komplexen Zusammenhänge stellt dies sowohl aus wissenschaftlich-technischer Sicht, als auch aus Anwendungssicht eine große Herausforderung dar. Mit dem Forschungsvorhaben “dataVIAS” sollen eigene Forschungserfolge auf diesem Gebiet fortgeführt und weiterentwickelt werden und praxis?relevante Herausforderungen für industrielle Anwendungsfälle identifiziert und gelöst werden. Die Klimaforschung ist eine beispielhafte Anwendungsdomäne, die von diesem Forschungsvorhaben profitieren kann und signifikante gesellschaftliche Auswirkungen hat. Visuell-Interaktive Such- und Analysewerkzeuge erlauben Analysten das frühzeitige Erkennen von Mustern in Wetter-Messdaten. Wetterwarnungen und vorbereitende Maßnahmen können so früher ergriffen und Sach- und Personenschäden entscheidend reduziert werden.
Ziel von “dataVIAS” war, mit Hilfe der Kombination von Data-Mining und Visualisierung, neue visuell-interaktive Methoden zur Suche und Analyse großer Datenmengen zu entwickeln.
Diese ermöglichen es Analysten, bislang unerkannte Zusammenhänge in komplexen Daten leichter zu entdecken und bewerten zu können. Ein zweiter wichtiger Punkt des Vorhabens hierbei ist es, dem Benutzer die inhaltsbasierte Suche im kompletten Datenbestand zu ermöglichen, und den Datenbestand anhand des Inhalts zu Gruppieren.
Dazu müssen sowohl aussagekräftige Deskriptoren und schnelle und effektive Indexstrukturen geschaffen werden, als auch Eingabeinterfaces und Methoden implementiert werden, die ein intuitives Suchen und Explorieren in komplexen Datenmengen erlauben. Diese technischen Neuentwicklungen resultierten in einem Prototypen, anhand dessen der Nutzen für industrielle Problemstellung qualitativ evaluiert werden kann.
Software Campus-Partner: TU Darmstadt, SAP SE
Umsetzungszeitraum: 01.01.2013 – 31.12.2013