Name des Teilnehmers: Dipl.-Ing. Christoph Boden
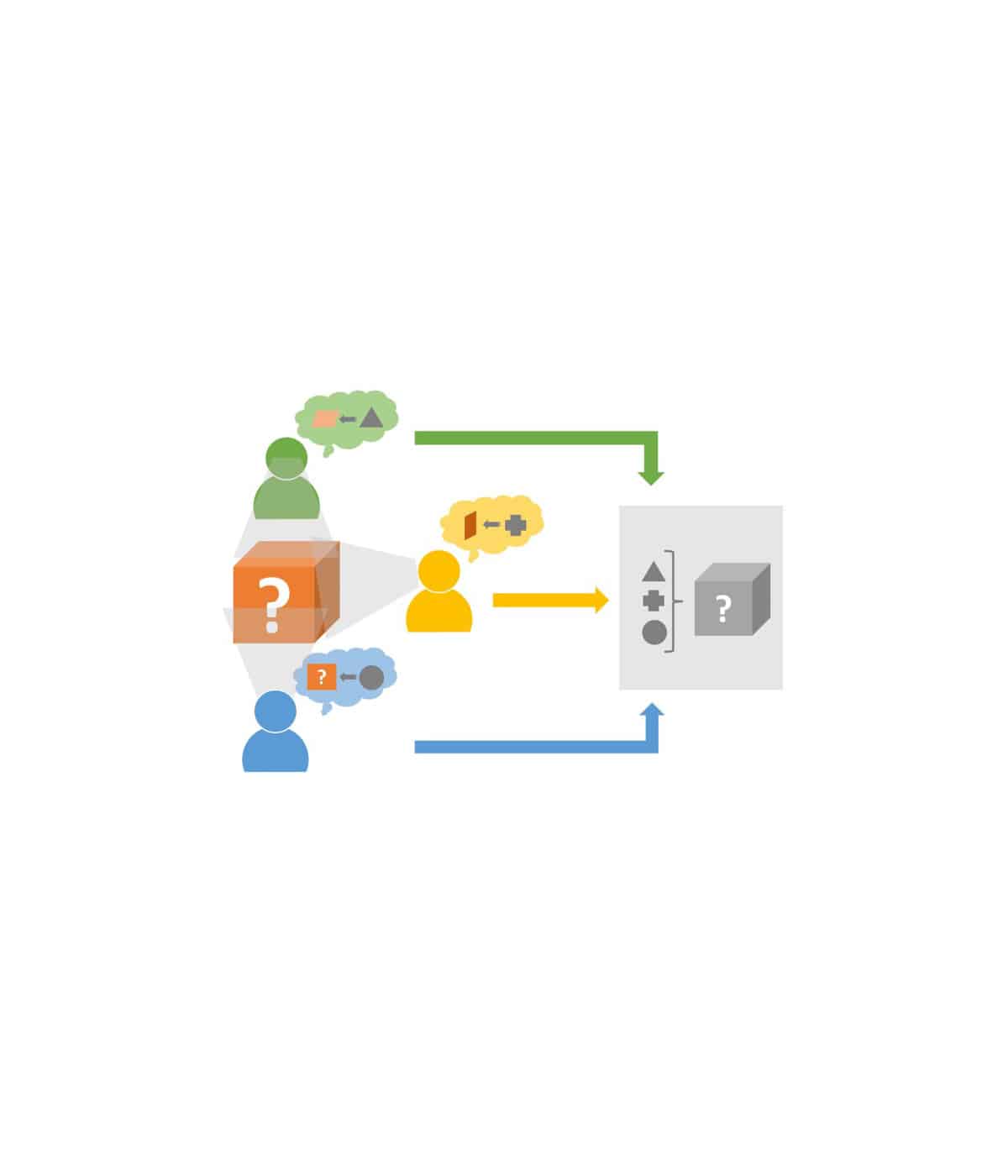
Beschreibung des IT-Forschungsprojektes: Unstrukturierte Informationen etwa in Form von Textdokumenten stellen die am schnellsten wachsende Quelle von Informationen für Unternehmen und Regierungen dar. Der überwiegende Teil der Daten im Worldwide Web sind Textdaten, die wertvolle Informationen und Fakten enthalten. Neuigkeiten, Meinungen und Stimmungen aus allen Domänen des täglichen Lebens verbreiten sich hier in Windeseile und machen die textuellen Inhalte des Webs somit zu einem unschätzbaren Reservoir auch für entscheidungsrelevante Informationen und Analysen für Entscheidungsträger in Wirtschaft und Verwaltung.
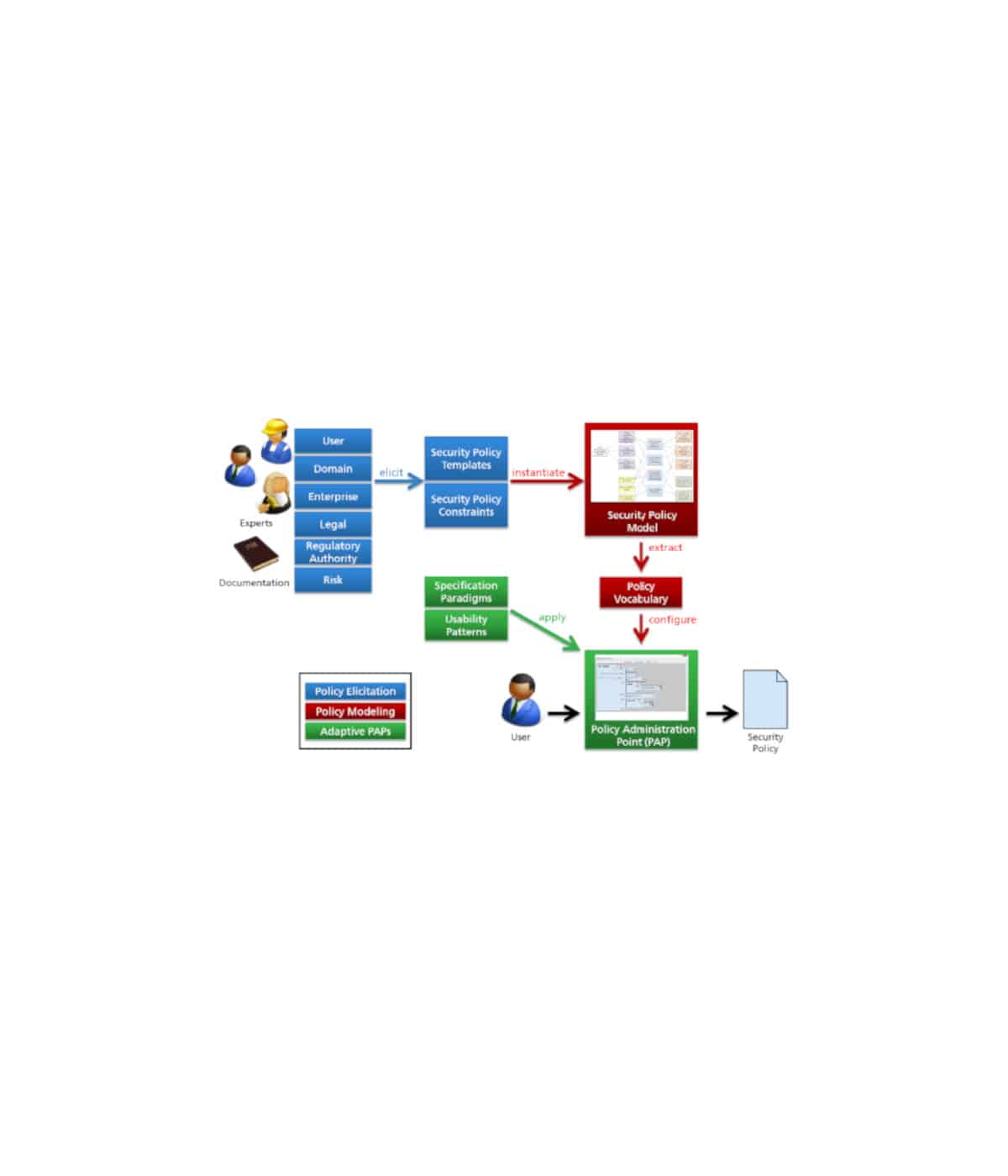
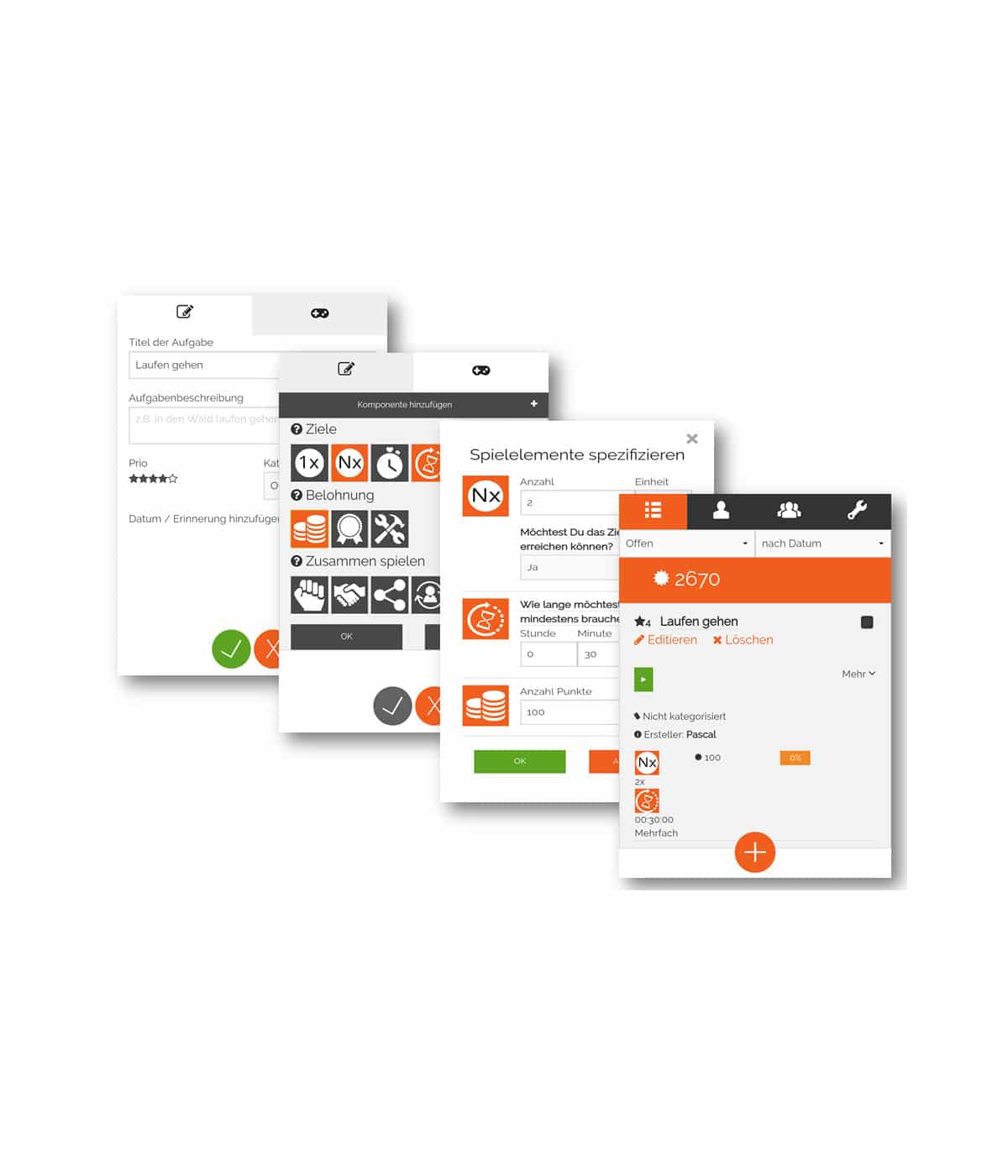
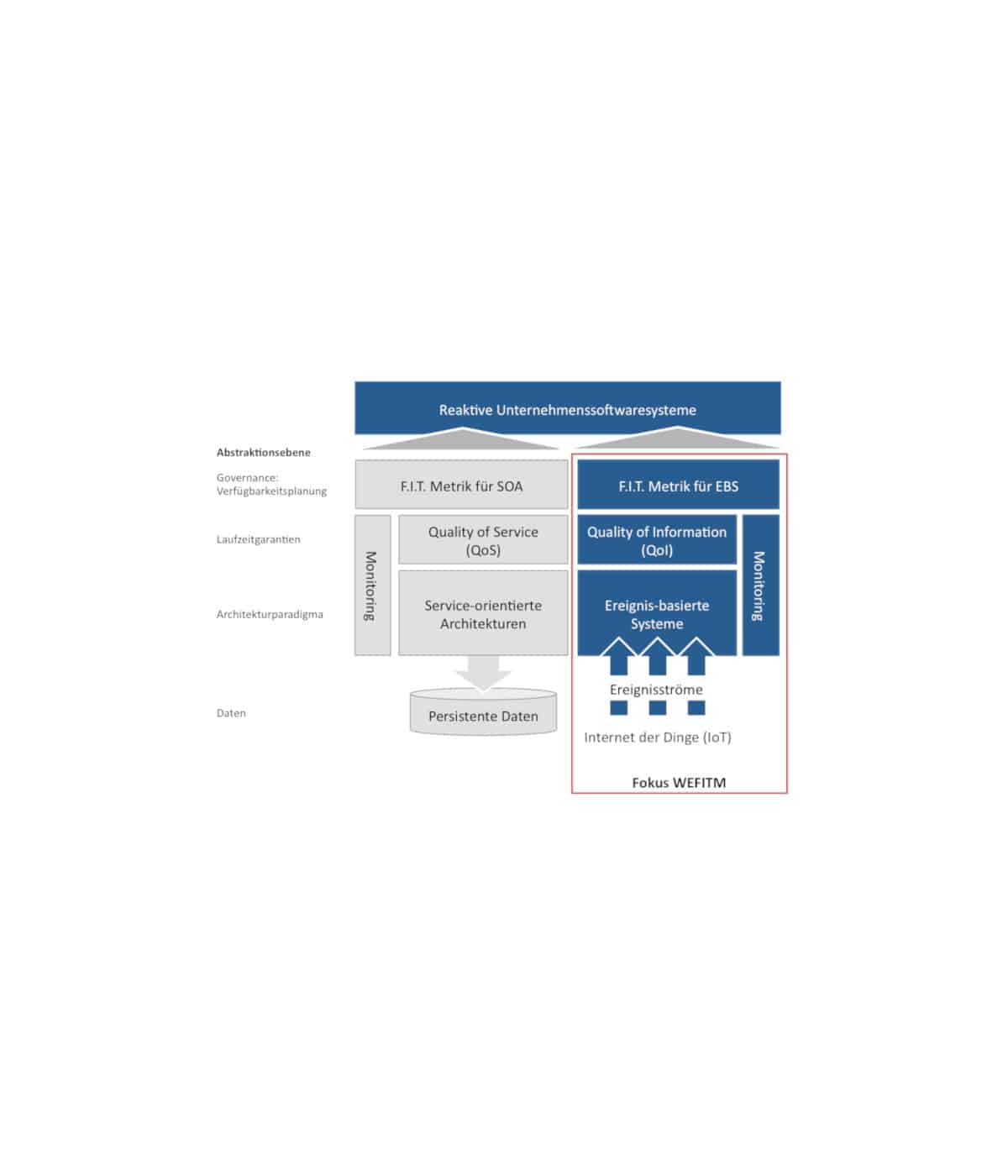
Es ist davon auszugehen, dass insbesondere die Integration von internen, strukturierten Daten des betrieblichen Informationssystems in Unternehmen sowohl aus operativen Reportingsystemen, als auch aus analytischen Data Warehouses mit den zumeist in textuellen Inhalten des Webs „versteckten“ externen Informationen einen besonderen Mehrwert schafft. Denkbar sind etwa eine aktuellere Analyse der Kreditwürdigkeit von Lieferanten und Kunden anhand der Konversationen im „social web“ oder ein effektiveres Forecasting und Risk-Management anhand der Analyse von Kundenstimmen im Netz. Im Rahmen dieses vom Bundesministerium für Bildung und Forschung geförderten IT-Forschungsprojektes wurde anhand prototypischer Implementierung von Analysealgorithmen demonstriert, wie aus unstrukturierten Textdaten des Webs, entscheidungsunterstützende Informationen extrahiert und aggregiert werden können.
Software Campus-Partner: TU Berlin, Software AG
Umsetzungszeitraum: 01.11.2012 – 31.10.2014