Name des Teilnehmers: Thomas Reschenhofer
Beschreibung des IT-Forschungsprojektes: In so gut wie allen Unternehmen von heute unterliegt die zur Verfügung stehenden Informationsmenge nicht nur einem ungeheuren Wachstum, sondern ebenso einer zunehmenden Vernetzung ihrer Informationsobjekte. Die Analyse dieser immer größer und komplexer werdenden Informationsmenge wird daher zu einer zentralen Herausforderung. Dabei müssen simultan die Analysen verschiedener Benutzergruppen zu verschiedenen Zeiten unterstützt werden. Um diese Herausforderung zu meistern, werden in der Praxis Desktop?Werkzeuge wie Microsoft Excel – allgemein als Spreadsheets bezeichnet – eingesetzt, um Endanwendern eine selbstständige und interaktive Aggregation und Visualisierung von flachen Datensätzen (Umsätze, Kosten, ) zu ermöglichen. Deren Anwendungsfelder reichen dabei von der Inventurverwaltung bis hin zum Finanz?Reporting. Ein ganz entscheidender Aspekt des Paradigmas ist dabei das Verbergen des Designs des Spreadsheets vor dem Anwender, da dieser seine Anwendung nicht explizit modellieren muss. Das Design des Spreadsheets wird implizit durch die Definition von Berechnungen (z.B. Summen über Spalten) und Visualisierungen (z.B. Tortendiagramme, Zeitreihen, etc.) festgelegt. Das Verbergen des Spreadsheet?Designs hat zwar eine hohe Flexibilität zur Folge, andererseits erschwert die Intransparenz der dabei entstehenden Abhängigkeiten die Nachvollziehbarkeit der Auswirkungen einer Änderung. So ist es beispielsweise nicht ersichtlich, welche Visualisierungen oder Berechnungen von einer bestimmten Zelle abhängig sind, insbesondere wenn Abhängigkeiten über mehrere Zellen hinweg bestehen. Aufgrund dieser Ungewissheit werden daher in der Praxis die Erstellung eines neuen Spreadsheets und damit die Erzeugung von Redundanzen der Änderung einzelner Berechnungen meist vorgezogen.
Dies trifft insbesondere dann zu, wenn Spreadsheets zwischen Fachanwendern ausgetauscht und Änderungen in fremden Spreadsheets vorgenommen werden. Das Visualisieren der Abhängigkeiten eines Spreadsheets würde dem Anwender hingegen bei der Evaluierung der Auswirkungen einer Änderung unterstützen. Des Weiteren stehen bei Spreadsheets wie Excel Berechnungen auf Basis zweidimensionaler Strukturen wie beispielsweise Zeitreihen und Tabellen im Vordergrund. Jede einzelne Zelle solch einer Struktur enthält dabei ein einfaches Objekt, z.B. eine Zahl, ein Datum, oder einfachen Text. Komplex strukturierte und vernetzte Objekte lassen sich in den Zellen eines Spreadsheets nicht darstellen. Diese Einschränkung führt dazu, dass Berechnungen mit komplexen Zwischenergebnisse oder Ausgaben in klassischen Spreadsheets nicht möglich sind.
Ein Beispiel für komplex strukturierte und vernetzte Objekte sind Baumstrukturen. Die Analyse einer beliebig tiefen Baumstruktur ist mit einem auf einfachen Objekten spezialisierten Spreadsheet nur sehr schwierig machbar. Ein Beispiel für komplexe vernetzte Daten sind netzwerkartige Strukturen, z.B. soziale Netzwerke und Logistik?Netze. Fragestellungen wie „Welcher Standort ist aufgrund seiner Erreichbarkeit am besten als zentraler Umschlagplatz geeignet?“ lassen sich in herkömmlichen Spreadsheets entweder gar nicht oder nur sehr schwer beantworten.
Zwar können komplex vernetzte Strukturen in Form von einer oder mehrerer Tabellen dargestellt werden (z.B. je eine Tabelle für Knoten und Kanten eines Graphen). Aufgrund der Beschränkung der Spreadsheet?Zellen auf einfache Ergebnistypen können diese komplex vernetzten Strukturen allerdings nicht das Ergebnis einer Berechnung sein.
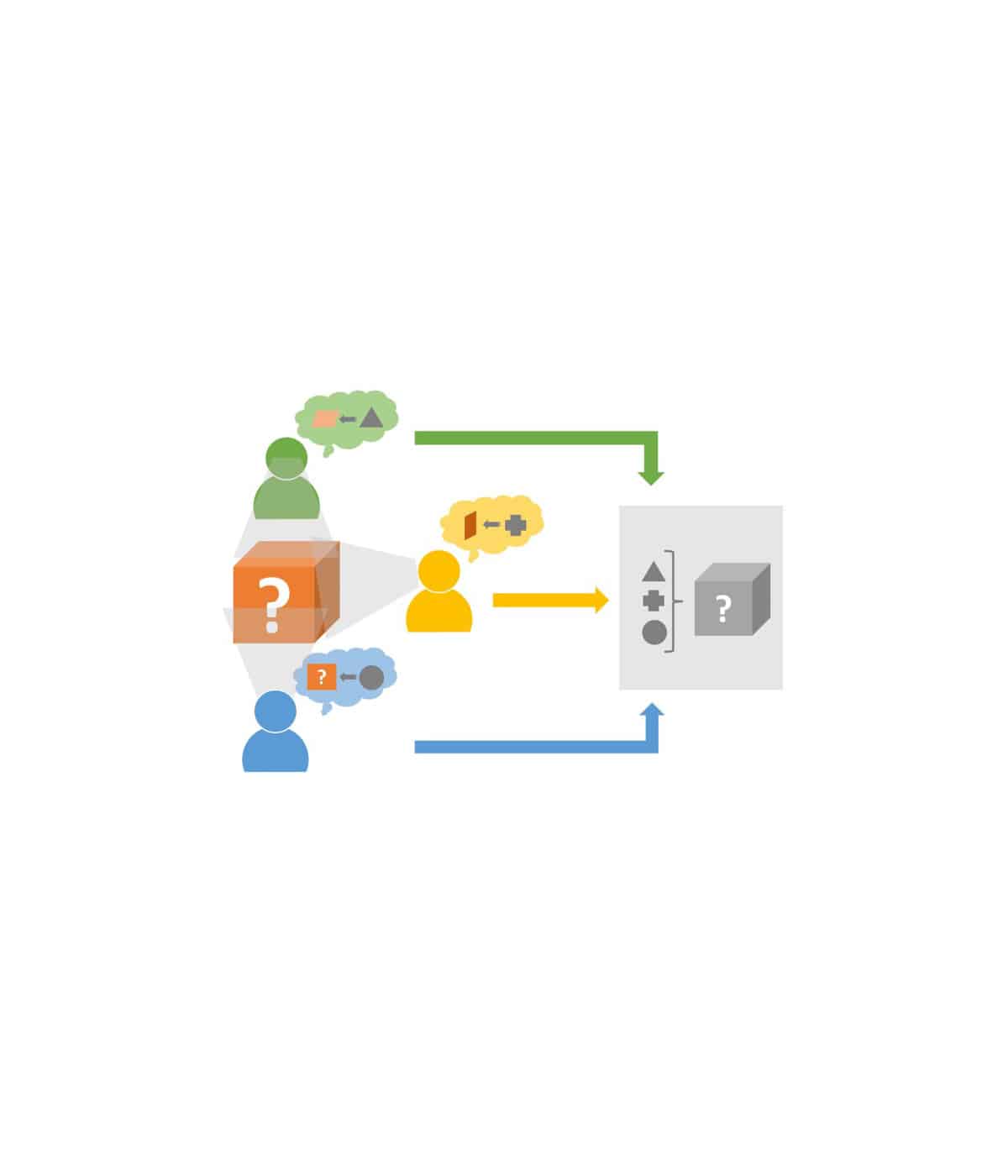
Ein weiteres Problem bestehender Spreadsheet-Anwendungen ist deren mangelnde Kollaborationsunterstützung: Während Geschäftsdaten meist durch eine Vielzahl an Benutzern und deren Zusammenarbeit generiert werden, werden diese zu Analysezwecken aus diesem kollaborativen Umfeld in eine Desktopanwendung transferiert. Dabei könnte die Analyse in einem kollaborativen Umfeld z.B. folgende Aspekte berücksichtigen: Welche Anwender entwerfen welche Daten, Funktionen und Visualisierungen? Welche Anwender sind für die Integrität welcher Daten und Funktionen zuständig? Welche Daten dürfen von welchen Anwendern gelesen werden? Wie haben sich die Struktur des Spreadsheets und die Werte des Spreadsheets über die Zeit entwickelt (Historisierung)?
Das Vorhabens Spreadsheet 2.0 adressiert folgenden Probleme aktuellen Spreadsheets:
1. Intransparenz der Abhängigkeiten zwischen Daten, Berechnungen und Visualisierungen
2. Mangelnde Unterstützung komplexer Datenstrukturen
3. Mangelnde Kollaborationsunterstützung
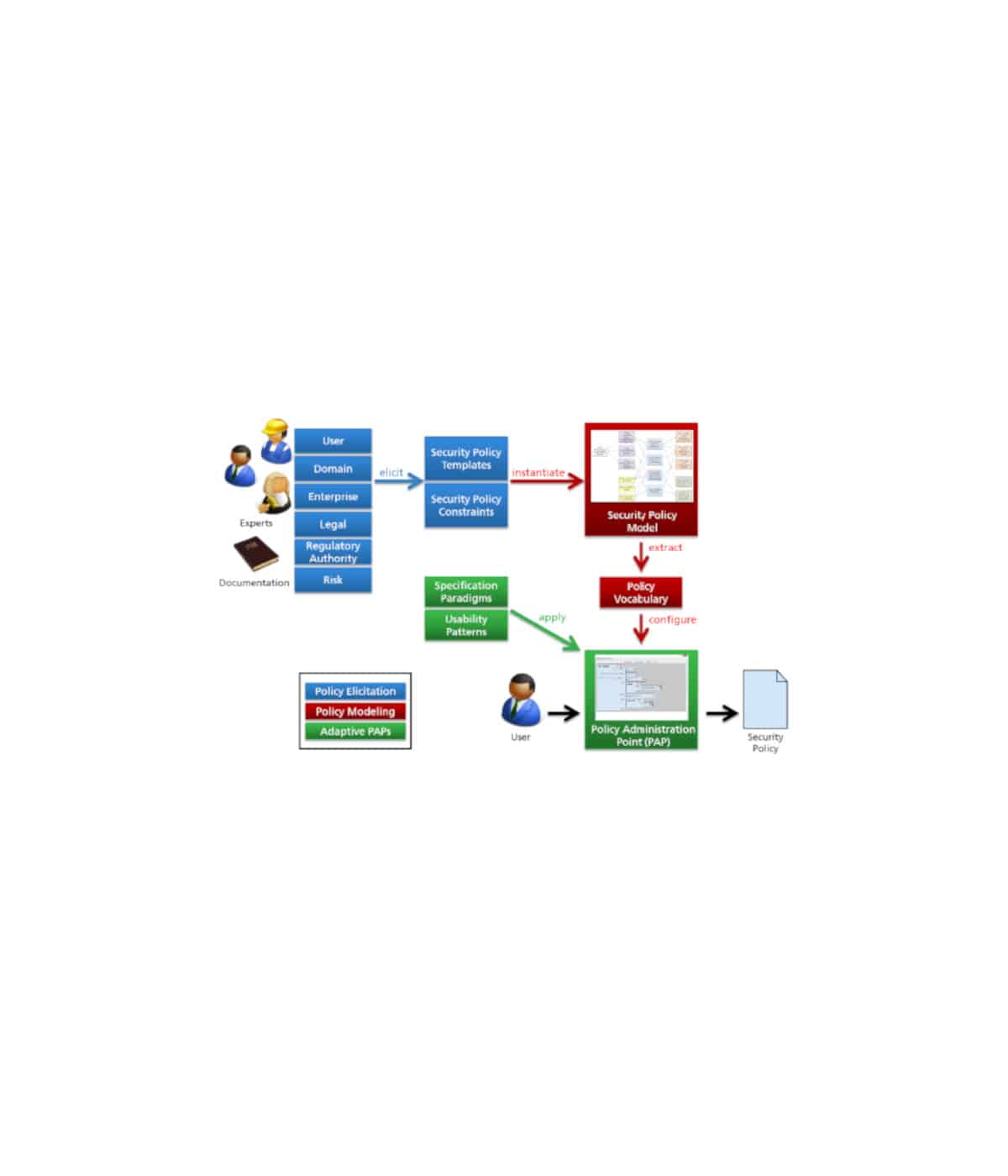
Die Intransparenz bei den Abhängigkeiten zwischen Daten, Berechnungen und Visualisierungen besteht im Wesentlichen darin, dass ein Anwender ausgehend von einer bestimmten Zelle nicht ohne weiteres feststellen kann, woher die Daten für die Berechnung stammen, ob sie überschrieben werden darf bzw. wo die Ergebnisse dieser Berechnung weiterverwendet werden. Eine Lösung dieses Problems ist der Entwurf von Spreadsheets durch die Modellierung der „Datenflüsse“ ausgehend von verschiedenen Datenquellen (z.B. Tabellen) über Berechnungseinheiten bis hin zu Visualisierungen der Daten. Der Benutzer stellt eine zusätzliche Komponente dar und nimmt durch dessen Berechtigungen, Informationsbedarfe und Zuständigkeiten Einfluss auf den Datenfluss.
Ziel des Spreadsheet 2.0-Ansatzes ist außerdem, den Datenfluss zwischen den Komponenten nicht nur auf einfache Datenobjekte (z.B. Zahl, Datum, Text) zu beschränken, sondern auch den Austausch komplexer vernetzter Datenstrukturen (z.B. verschachtelte Baum als auch Netzwerkstrukturen) zu erlauben. Einzig die Kompatibilität zweier Komponenten zueinander muss gewahrt werden, d.h. die Ausgabe einer Komponente muss als Eingabe einer darauf folgenden akzeptiert werden, unabhängig von der Komplexität der auszutauschenden Datenobjekte.
Schließlich sollen in der Entwicklung Informationen aus dem kollaborativen Umfeld beim Entwurf der Spreadsheet 2.0-Struktur und der Ausführung der Berechnungen berücksichtigt werden. Dies schließt die Berechtigungen, Verantwortlichkeiten und Informationsbedarfe der Anwender ein.
Software Campus-Partner: TU München, Deutsche Post DHL
Umsetzungszeitraum: 01.03.2014 – 29.02.2016