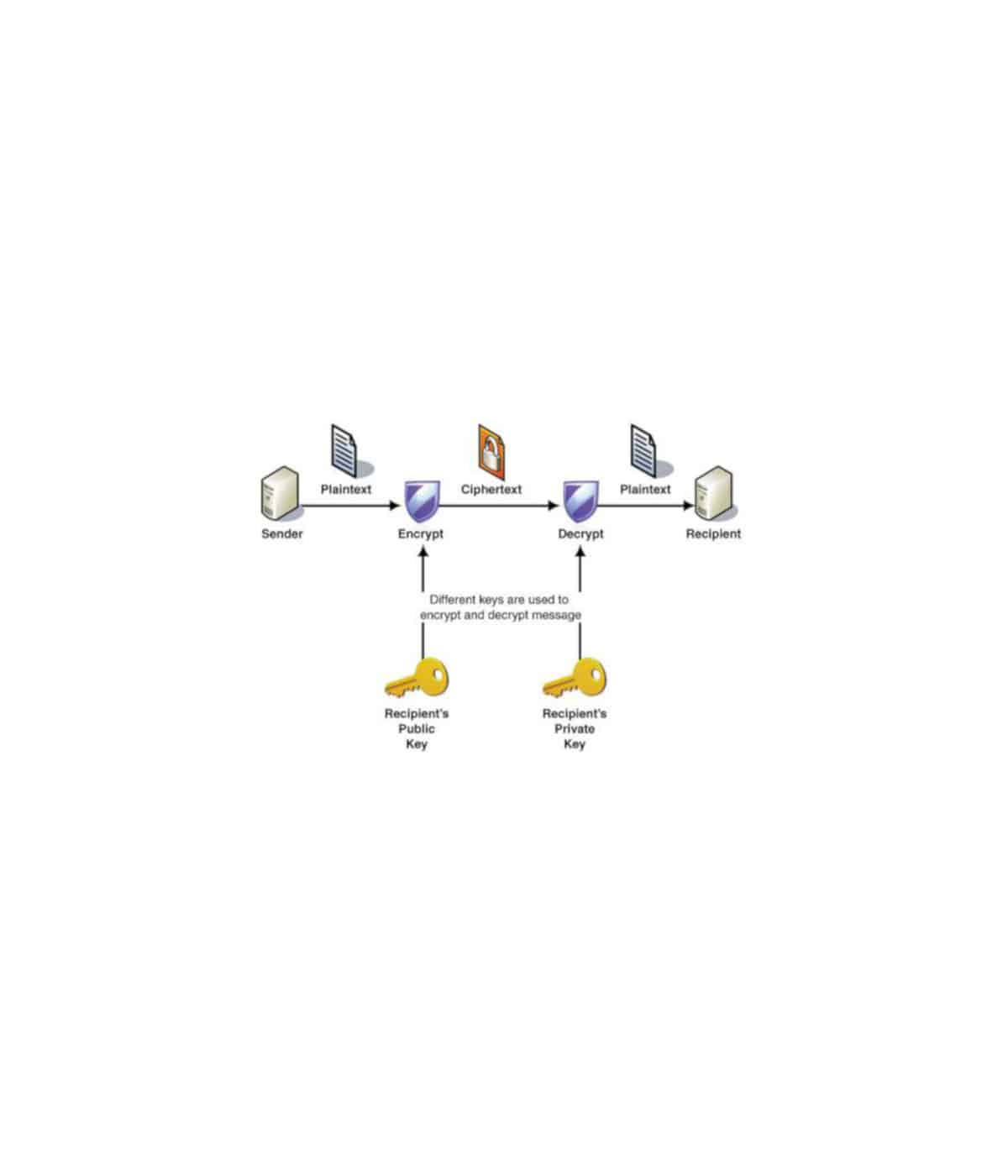
Name of the participant: Tarek Saier
Description of the IT research project: The ongoing increase in global research activity faces scientists with a constantly growing challenge of information overload. In some research fields, it is no longer possible for people to read all the relevant new publications, even within a narrowly defined framework. Such problems are countered by efforts to automate the processing of academic literature. Here, metadata-based tools such as bibliometric metrics or keyword searches have been available for a long time and can already provide a certain degree of relief in tasks such as literature searches. Due to the advancing implementation of Open Access strategies on the part of scientific publishers as well as new developments in computational linguistics, there are now more and more possibilities to process not only metadata but also publication full texts in an automated way and thus to use them to support research activities.
The goal in the project [KOM,BI]is to support the identification of high-potential research projects. More specifically, “academic artifacts” – results of already published research such as methods and data sets – are to be identified whose combined use is highly prospective. To this purpose, the previous use, transformation, and combination of artifacts, as well as the context of these processes in terms of the publications themselves and their contributions and influence, will be recorded in large academic corpora in an automated way. Models trained on this data using supervised machine learning can make subsequent predictions about combinations of given artifacts not yet described in the literature. These predictions will help scientists identify research projects that hold potential.
Software Campus partners: KIT, Holtzbrinck Publishing Group
Implementation period: 01.04.2022 – 31.07.2023